
この記事では実際に行う際にPythonやHTMLを使うので以下の読者を想定しています。
- Pythonの基本的な文法を理解している人
- HTMLの基本的な要素(<div>や<table>タグ等)を理解している人
スクレイピングはWebページのHTML構造に依存します。
ページのデザインが変わるとプログラムも変える必要があることに注意してください。
HTMLがよくわからない方はいずれにしても、今後のためにどこかでまとめて勉強する必要があります。
幸いなことに無料で優良なサイト等もありますので、興味がある方は参考にしてください。
また、Pythonでスクレイピングを行うための環境構築についての説明はここでは行いません。
お済みでない方は他の記事を参考にするようお願いします。
目次
Webスクレイピングとは
Webスクレイピングとは、Webページからデータを自動的に収集するのことです。
この技術のメリットはプログラムを動かすだけで、わざわざページをその都度見にいかずに情報を収集できる点です。
今回は、データ解析に非常に向いている言語であるPythonを使い、実際にWebスクレイピングのハンズオンを行います。
是非皆さんも手を動かしてやってみましょう。
Webスクレイピングを行うにあたっての注意事項
Webページから情報収集する際には注意しなければならないことがあります。
まず、そのページに載っているデータには著作権がある場合があります。
そういった場合、無断でそのデータを抜き取り使うことは当然違法です。
また、そのWebページが使用しているサーバーの負荷も気にしなければなりません。
Webスクレイピングでは、プログラムで接続するため相手のサーバーに対して負荷をかけます。
それによって相手のサーバーが自分のコンピューターからの接続をブロックしてしまうことがあります。
自分だけならまだ良いかもしれませんが、公共のパソコン(例えば学内等)で規制された場合は、他の人にも迷惑がかかるかもしれません。
スクレイピングをする前に、対象のWebページなどを確認するようにしましょう。
Webページから情報を取る
今回はカリフォルニア大学の予算に関する報告書のページから、Legislative reportsのデータを収集したいと思います。
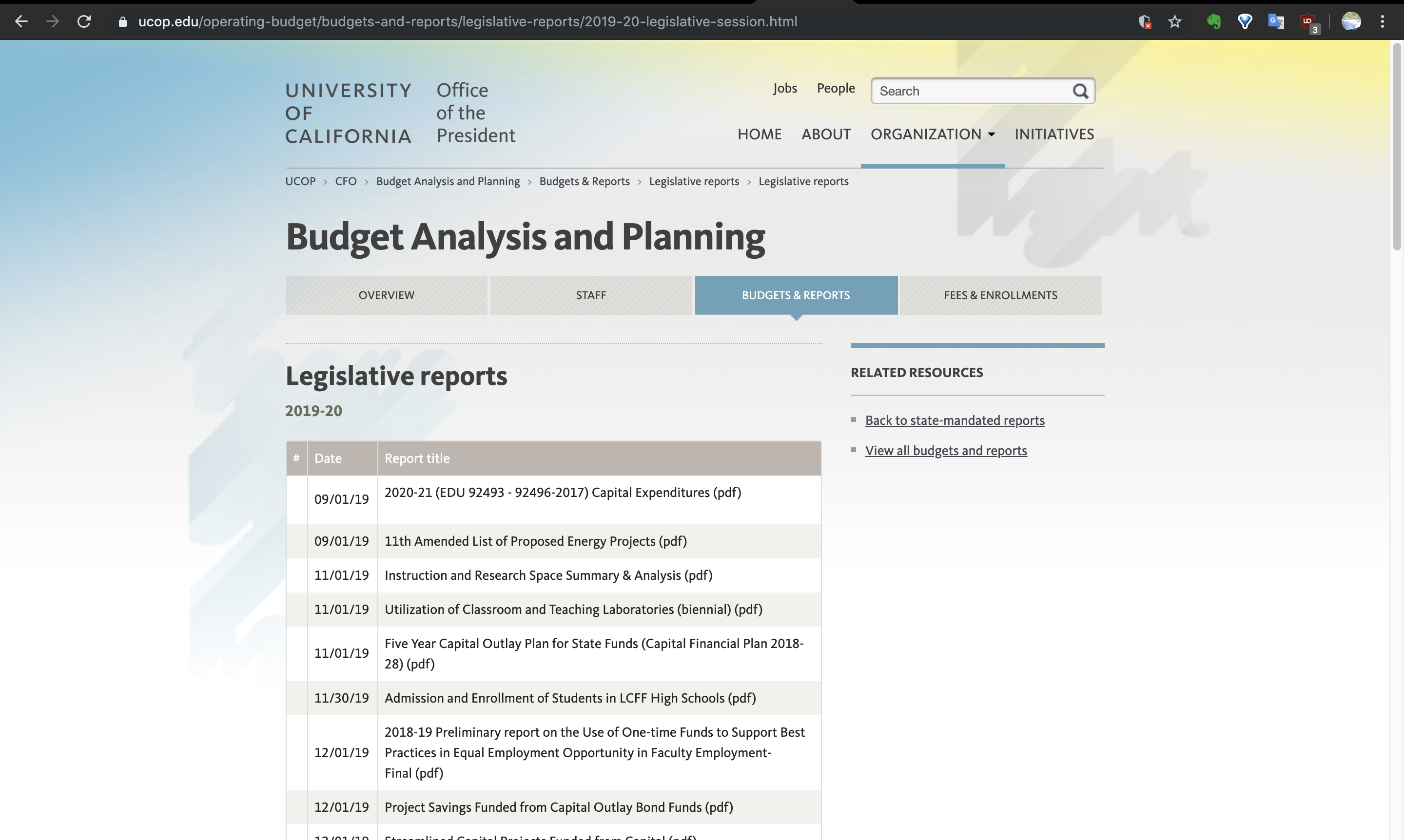
まずは必要なライブラリをインポートします。
お済みでない方はpipコマンドを用いてインストールしてください。
from bs4 import BeautifulSoup
import requests
import pandas as pdでは、まず最初に該当ページのHTMLを取得します。
url = 'https://www.ucop.edu/operating-budget/budgets-and-reports/legislative-reports/2019-20-legislative-session.html'
# HTML要素を取得する
result = request.get(url)
c = result.contentこれでページ上の全てのHTMLが取得できました。
確認してみましょう。
c[:300]b'\n<!DOCTYPE html>\n<!--[if lt IE 9]><html class="lte-ie8 no-js" lang="en"><![endif]-->\n<!--[if gt IE 8]><!--><html lang="en" class="no-js"><!--<![endif]-->\n<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">\n<head>\n<meta content="IE=edge" http-equiv="X-UA-Compatible" />\r\n<meta charset'しかしこの状態だと要素ごとの改行がなく、扱いづらいです。
BeautifulSoupを使い整形します。
# HTMLをもとに、整形されたページ全体のオブジェクトを作る
soup = BeautifulSoup(c)soup<!DOCTYPE html>
<!--[if lt IE 9]><html class="lte-ie8 no-js" lang="en"><![endif]--><!--[if gt IE 8]><!--><html class="no-js" lang="en"><!--<![endif]-->
<head>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<meta charset="utf-8"/>
... ベージ全体の情報を抜き取ることができました。
ここから更に必要な部分を抜き出していきます。
使用しているブラウザがGoogle Chromeであれば右クリックから検証を押すことでパーツごとのHTML要素を確認できます。
以下のように<div class="list-land" id="content">の部分が、欲しいテーブルデータの部分を含んでいることが分かります。
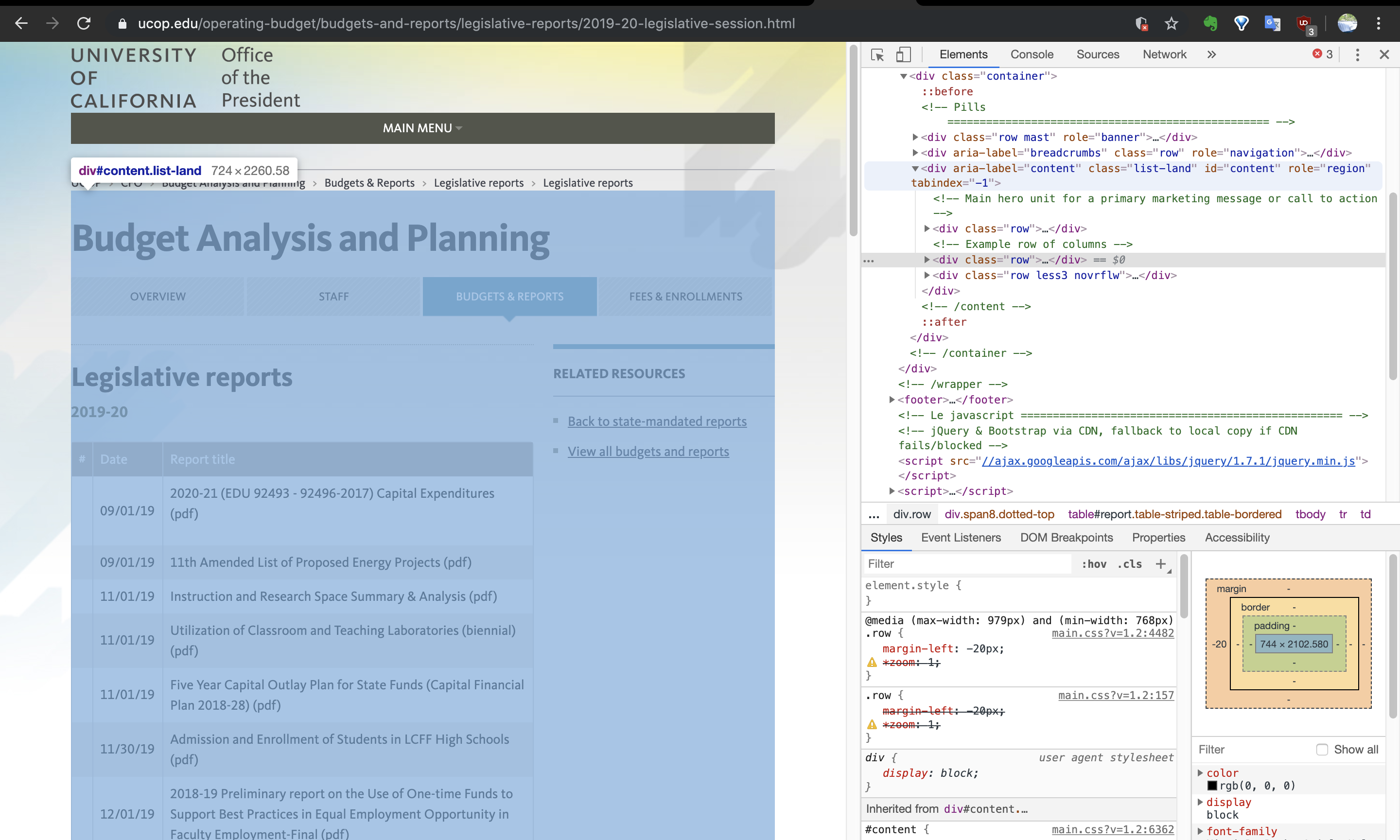
この情報から目的の部分(HTML要素)を切り出します。
# HTML要素で絞る
summary = soup.find("div",{'class':'list-land','id':'content'})
# tableを抜き出す
tables = summary.find_all('table')今回は上記のdivの範囲にtableは1つしかなかったので、簡単に絞り込めました。
ここから更に絞ります。
その前にテーブルはHTMLではどのように表現されているか、簡単に復習しておきます。
そもそもtableタグとは、下記のような構造で表を表現しています。
<tr>
<td>Content1-1</td>
<td>Content1-2</td>
</tr>
<tr>
<td>Content2-1</td>
<td>Content2-2</td>
</tr>なので<tr>タグの行から<td>タグの情報を取る流れでプログラムを組むことができます。
# 空のリストを用意する
data = []
rows = tables[0].find_all('tr')
# for文で回して<td>のデータをdataに入れる
for tr in rows:
cols = tr.find_all('td')
for td in cols:
text = td.find(text=True)
data.append(text)dataの中身を確認するとテーブルの情報がリストに格納されていることを確認できます。
data[None,
'09/01/19',
'\n',
None,
'09/01/19',
'11th Amended List of Proposed Energy Projects (pdf)',
None,
'11/01/19',
'Instruction and Research Space Summary & Analysis (pdf)',
...欲しいデータが集まって来ました。
ただしこのままですと、Noneのような不必要なデータも含まれていますし、リストに入っているだけでまとまっていないので非常に見づらいですね。
なのでここから更に見やすくデータを整形したいと思います。
データを整形する
今回は上記のデータの中でpdfと書かれたものだけ抜き出してデータを作っていきます。
その際に日付も重要な情報ですので、保持することにします。
dataのタイトル部分に\xa0という謎の文字列が入っていますが、これはエンコードのエラーなので取り除きます。
# タイトルと日付を格納する空のリストを用意する
reports = []
date = []
index = 0
# for文でリストのそれぞれの要素をitemに格納
for item in data:
# pdfという文字列が入っていればreportに入れる
# dateはタイトル文字列の1つ上にあるので、index-1で指定する
if 'pdf' in str(item):
date.append(data[index-1])
# 不要なデータを取り除く
reports.append(item.replace('\xa0', ' '))
index += 1これでreportsとdateにそれぞれ目的のデータが入りました。
後はそれぞれのデータを結合するだけです。
date = pd.Series(date)
reports = pd.Series(reports)
web_df = pd.concat([date, reports], axis=1)
# タイトルを付ける
web_df.columns = ['Date', 'Reports']これで目標としていたテーブルが完成しました。
確認してみましょう。
web_df| Date | Reports | |
|---|---|---|
| 0 | 09/01/19 | 11th Amended List of Proposed Energy Projects … |
| 1 | 11/01/19 | Instruction and Research Space Summary & Analy… |
| 2 | 11/01/19 | Utilization of Classroom and Teaching Laborato… |
| 3 | 11/01/19 | Five Year Capital Outlay Plan for State Funds … |
| 4 | 11/30/19 | Admission and Enrollment of Students in LCFF H… |
| 5 | 12/01/19 | 2018-19 Preliminary report on the Use of One-t… |
| 6 | 12/01/19 | Project Savings Funded from Capital Outlay Bon… |
| 7 | 12/01/19 | Streamlined Capital Projects Funded from Capit… |
| 8 | 01/01/20 | Annual General Obligation Bonds Accountability… |
| 9 | 01/01/20 | Small Business Utilization (pdf) |
| 10 | 01/01/20 | Psychiatry GME (pdf) |
| 11 | 01/01/20 | Office of the Chief Investment Officer (pdf) |
| 12 | 01/10/20 | Summer Enrollment (pdf) |
| 13 | 01/15/20 | Contracting Out for Services at Newly Develope… |
| 14 | 02/01/20 | Capital Expenditures Progress Report (EDU 9249… |
| 15 | 02/01/20 | Statewide Energy Projects (SEP) – Progress (pdf) |
| 16 | 02/01/20 | Hunger-free Campus (pdf) |
| 17 | 03/01/20 | Data on Student Transfers (pdf) |
| 18 | 03/01/20 | Entry Level Writing Requirement (ELWR) (pdf) |
| 19 | 03/15/20 | Performance Outcome Measures (pdf) |
| 20 | 03/31/20 | Annual Report on Student Financial Support (pdf) |
| 21 | 04/01/20 | 0220 UC Riverside School of Medicine (pdf) |
| 22 | 04/01/20 | Unique Statewide Pupil Identifier (pdf) |
| 23 | 04/01/20 | Systemwide and Presidential Initiatives (pdf) |
| 24 | 04/01/20 | Plan to Limit Nonresident Enrollment (pdf) |
| 25 | 09/01/20 | 2021-22 (EDU 92493 – 92496-2017) Capital Expen… |
| 26 | 09/01/20 | 12th Amended List of Proposed Energy Projects … |
| 27 | 11/01/20 | Instruction and Research Space Summary and Ana… |
| 28 | 11/01/20 | Utilization of Classroom and Teaching Laborato… |
| 29 | 11/30/20 | Five Year Capital Outlay Plan for State Funds … |
| 30 | 12-31-20 | Breast Cancer Research Program (pdf) |
| 31 | 12-31-20 | Cigarette and Tobacco Products Surtax Research… |
| 32 | 01-01-21 | California Subject Matter Programs (CSMP) (pdf) |
| 33 | 04-01-21 | California State Summer School for Mathematics… |
| 34 | 06/30/21 | University Extension Programs (pdf) |
綺麗にテーブルを構築できました。
まとめ
今回はWebスクレイピング入門ということで、pythonを使ってデータを集めて整形するところまで行いました。
Webスクレイピングなどのデータ解析は、HTML要素のどこからデータを取れるのかやデータをどのように整形すれば綺麗になるか等、行う人の工夫が活きてくる非常に面白い技術です。
是非みなさんもどうすればもっと良くなるか、たくさんコードを書いて実践してみてください。
本気でプログラミングを身につけるならCodeShip

CodeShipは業界内で唯一「無償延長保証制度」によるスキル修得を保証しているプログラミングスクールです。
独学での挫折や未経験からでも、スタートアップベンチャーや日系・外資の大手WEB系企業まで幅広くエンジニアを輩出する教育実績を残しています。
勉強目的ごとに用意された6つの学習コースと現役エンジニア、キャリアコンサルタントがあなたの「開発スキル修得」と「キャリアプランニング」をサポートします
さらに、期間内であれば選択した以外のコースのカリキュラムを受講可能。
同じ値段で、頑張った分だけ勉強できる「勉強し放題」はCodeShipだけ。
まずはご自身のプログラミング学習やキャリアプランについて、無料個別相談会にてお気軽にご相談ください。

